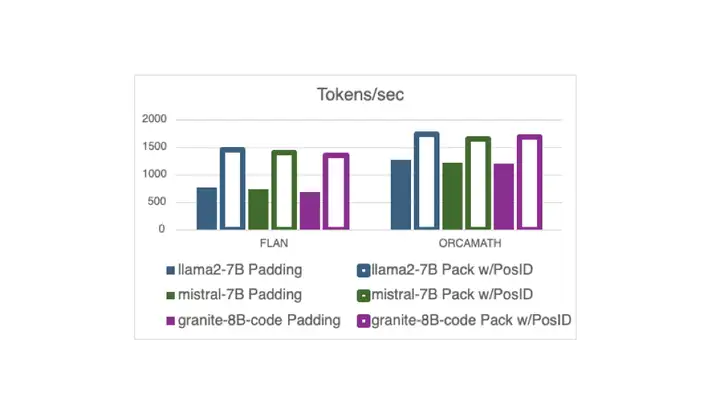
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!
来自主题: AI资讯
2358 点击 2024-09-18 15:44
 搜索
搜索
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!

众所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个 GPU。以 LLaMA2 70B 模型为例,其训练总共需要 1,720,320 GPU hours。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。